Read on to see how the experts of Lucy in the Cloud created a new solution that makes it possible to crunch in pseudo real-time huge datasets including load curves and expose them for analytics and ML usage, for a big player in the energy sector.
What was the challenge that we were approached with?
Our client came to the experts of Lucy with a clear challenge to help solve: they were dealing with very large data sets, that didn’t have clean update markers in proprietary ERP solutions. As such they were in need of a solution that could meet the following requirements:
A uniform data platform and data lake, including real-time capabilities
Responsive self-service BI and Dashboarding capabilities
Ability of the platform to address more ML/AI oriented used cases
Agility in deployment in a controlled and governed landscape
And our experts wasted no time in going to work on a strategy and technical solution that would solve the main issues of our client. So what did we come up with?
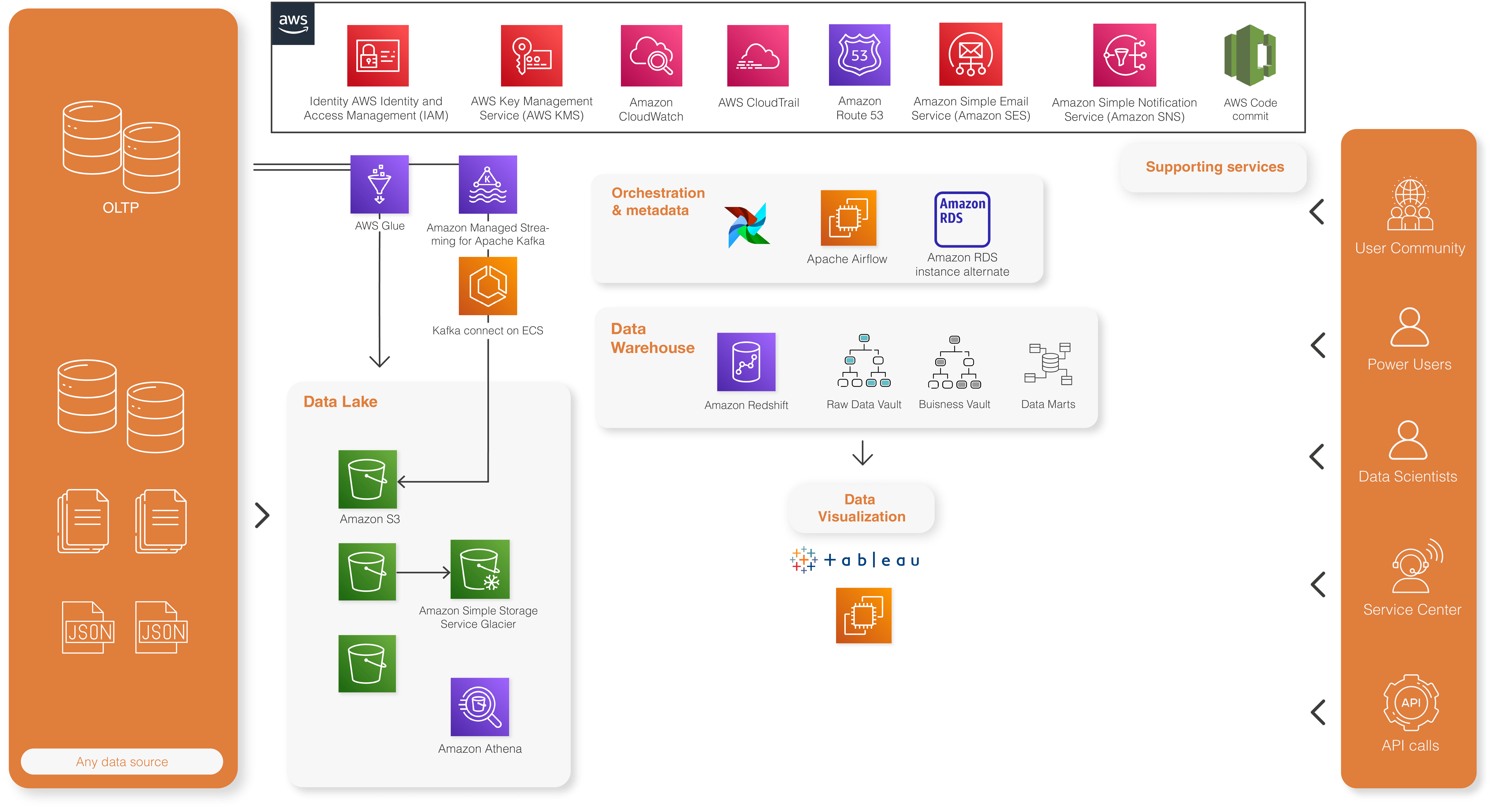
Our solution: a Data Lake solution using Redshift
Architecture based upon key data services of AWS
Data lake solution with Redshift and Tableau for DataViz
Our experts relied on the Tableau map capabilities to visualize any smart meter in the network including all its consumption metrics.
Tableau’s rich dashboarding capabilities make it possible to report and visualize all business metrics in a uniformed set, which is exactly what our customer was looking for..
Redshift giving a unified business data model, with a low time to sync from the source systems
The Data Warehouse is running on Amazon Redshift and follows the Data Vault 2.0 methodology. Data Vault objects are very standardized and have strict modelling rules, which allows a high level of standardization and automation. The data model is generated based on metadata stored in an Amazon RDS Aurora database. The Data Vault model is generated by Orion, a Lucy in the cloud developed Data Vault automation engine that runs in a serverless mode. The serverless mode is achieved by generating AWS Step Functions that executes Lambda functions and runs Redshift queries that are dispatched trough the Redshift data API.
This makes the solution very scalable and able to process in near real-time.
Real time flow based on AWS MSK and Kafka connect
In order to sync any database data based on Change Data Capture (CDC), Kafka connect is used running Debezium. The Kafka connect nodes are running under Docker in high availability mode. The data is serialized in AVRO format, the schema registry is deployed on ECS in HA mode. Having the serialization in AVRO format makes it’s fast and optimal in storage. AWS MSK handles giving the data platform is solid back bone to handle any real-time data case for now and in the future.
And much more!
The uniform Data Platform we have built for this key player in the Energy sector, grows fast and enables them to address all sorts of data related use cases including the use of Machine Learning and Artificial Intelligence capabilities.
Want to know more about the capabilities of Amazon Redshift?