Amazon Redshift : le cloud data warehouse le plus rapide et le plus utilisé
Le cas d’utilisation en matière de gestion de données consiste à unifier des sources de données disparates en un seul endroit et à exécuter des analyses personnalisées pour votre entreprise.
Avec un riche écosystème de fournisseurs d’intégration de données, il est facile de construire des pipelines vers ces sources et d’alimenter les données dans Redshift. Ajoutez-y un puissant outil de BI / Tableau de bord, et vous obtenez une pile BI complète. – XAVIER LEGRAND, LUCY IN THE CLOUD
L’un des principaux avantages de Redshift est sa simplicité. Auparavant, il fallait des mois pour mettre en place un Data Warehouse et le rendre opérationnel.
Ce n’est plus le cas aujourd’hui !
Vous pouvez faire tourner un cluster Redshift en moins de 15 minutes, et construire une pile de BI complète en un week-end.
Amazon Redshift
Analysez toutes vos données avec le Cloud Data Warehouse le plus rapide et le plus utilisé.
Analysez toutes vos données
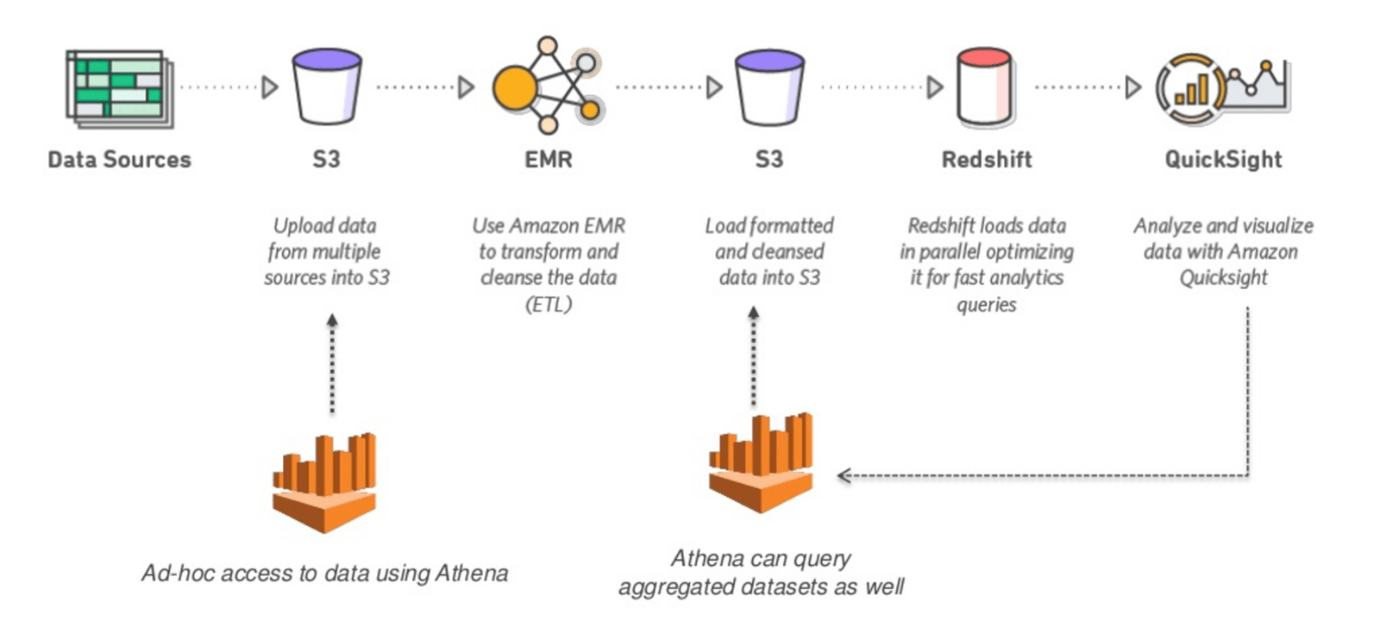
Aucun autre entrepôt de données ne permet d’obtenir aussi facilement de nouvelles informations à partir de toutes vos données. Avec Redshift, vous pouvez interroger et combiner des exaoctets de données structurées et semi-structurées dans votre Data Warehouse, votre base de données opérationnelle et votre Data Lake à l’aide de SQL standard. Redshift vous permet de sauvegarder facilement les résultats de vos requêtes dans votre Data Lake S3 en utilisant des formats ouverts, comme Apache Parquet, afin que vous puissiez effectuer des analyses supplémentaires à partir d’autres services d’analyse comme Amazon EMR, Amazon Athena et Amazon SageMaker.
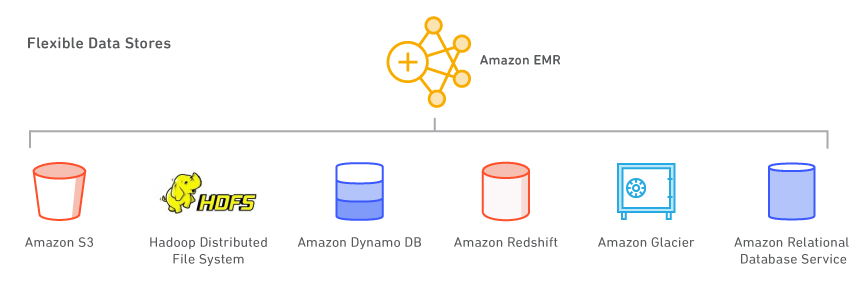
Amazon EMR est la plateforme cloud big data leader du marché pour le traitement de grandes quantités de données à l’aide d’outils open source tels que Apache Spark, Apache Hive, Apache HBase, Apache Flink, Apache Hudi et Presto. Amazon EMR facilite la mise en place, l’exploitation et la mise à l’échelle de vos environnements de big data en automatisant les tâches fastidieuses telles que l’approvisionnement en capacité et le réglage des clusters.
Avec EMR, vous pouvez exécuter des analyses à l’échelle du pétaoctet à moins de la moitié du coût des solutions traditionnelles sur site et plus de 3 fois plus vite que Apache Spark standard. Vous pouvez exécuter des charges de travail sur des instances Amazon EC2, sur des clusters Amazon Elastic Kubernetes Service (EKS) ou sur site en utilisant EMR sur AWS Outposts.
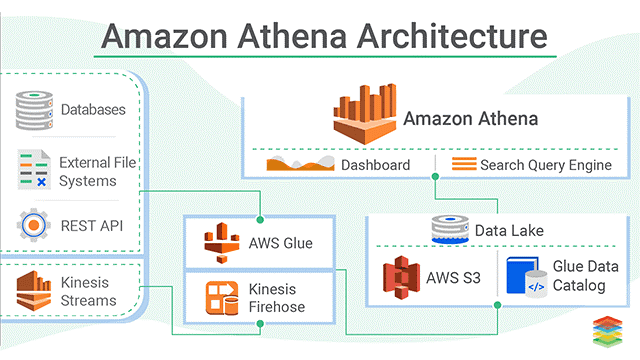
Amazon Athena est un service de requêtes interactives qui facilite l’analyse des données dans Amazon S3 à l’aide de SQL standard. Athena est sans serveur, il n’y a donc pas d’infrastructure à gérer, et vous ne payez que pour les requêtes que vous exécutez.
Athena est facile à utiliser. Il suffit de pointer vers vos données dans Amazon S3, de définir le schéma et de commencer à effectuer des requêtes à l’aide de SQL standard. La plupart des résultats sont livrés en quelques secondes. Avec Athena, il n’est pas nécessaire d’effectuer des tâches ETL complexes pour préparer vos données à l’analyse. Il est donc facile pour toute personne ayant des compétences en SQL d’analyser rapidement des ensembles de données à grande échelle.
Amazon SageMaker aide les scientifiques et les développeurs de données à préparer, construire, former et déployer rapidement des modèles d’apprentissage automatique de haute qualité en rassemblant un large éventail de fonctionnalités conçues spécialement pour l’apprentissage automatique.
Amazon QuickSight est un service de business intelligence (BI) évolutif, sans serveur, intégrable et alimenté par l’apprentissage automatique, conçu pour le cloud. QuickSight vous permet de créer et de publier facilement des tableaux de bord BI interactifs qui incluent des informations alimentées par l’apprentissage automatique. Les tableaux de bord QuickSight sont accessibles depuis n’importe quel appareil et peuvent être intégrés de manière transparente dans vos applications, portails et sites Web.
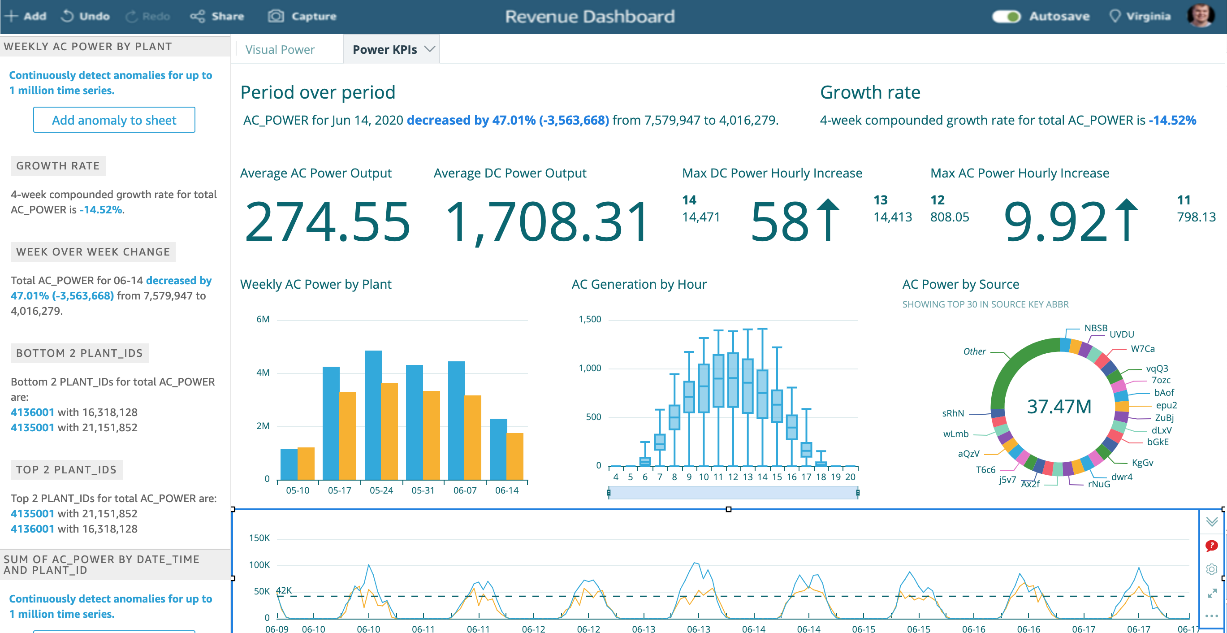
QuickSight est sans serveur et peut évoluer automatiquement vers des dizaines de milliers d’utilisateurs sans infrastructure à gérer ni capacité à prévoir. Il s’agit également du premier service BI à proposer une tarification à la session, où vous ne payez que lorsque vos utilisateurs accèdent à leurs tableaux de bord ou à leurs rapports, ce qui le rend rentable pour les déploiements à grande échelle.
Avec QuickSight, vous pouvez poser des questions commerciales à vos données en langage clair et recevoir des réponses en quelques secondes.
Des performances à toute échelle
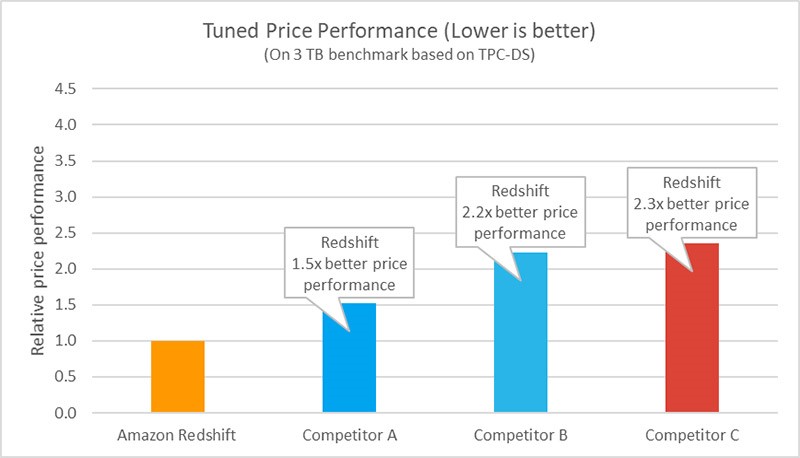
Le rapport prix/performance d’Amazon Redshift est jusqu’à 3x supérieur à celui des autres Cloud Data Warehouse, et l’avantage prix/performance s’améliore à mesure que votre Data Warehouse passe des gigaoctets aux exaoctets.
Amazon Redshift tire parti du matériel conçu par AWS et de l’apprentissage automatique (ML) pour offrir les meilleures performances en termes de prix, quelle que soit l’échelle. Cela inclut l’utilisation du système AWS Nitro pour accélérer la compression et le cryptage des données, des techniques ML pour analyser les requêtes et des algorithmes d’optimisation des graphes pour organiser et stocker automatiquement les données afin d’accélérer les résultats des requêtes.
Découvrez la nouvelle génération de Redshift avec AQUA (Advanced Query Accelerator)
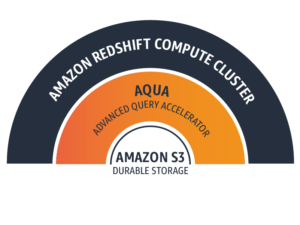
AQUA est un nouveau cache distribué et accéléré par le matériel qui permet aux requêtes Redshift de s’exécuter jusqu’à 10 fois plus vite que d’autres Cloud Data Warehouse d’entreprise en boostant automatiquement certaines opérations. AQUA accélère les opérations de balayage, de filtrage et d’agrégation aujourd’hui, et accélérera d’autres opérations à l’avenir.
Success Stories avec Amazon Redshift
Vous voulez savoir comment nous avons utilisé la puissance d’Amazon Redshift pour résoudre les problèmes de données de nos clients ?
Cliquez sur l’une des success stories ci-dessous pour en savoir plus !
ENERGIE – Création d’un Data Lake de données uniformes
ASSURANCE MALADIE – Réduire le travail de SAV et obtenir des informations sur les raisons des appels