Découvrez comment les experts de Lucy in the Cloud ont créé une nouvelle plateforme qui permet de traiter en quasi temps réel de grandes quantités de données, notamment les courbes de charge émanant des compteurs intelligents, afin de les visualiser sur une carte ou de les traiter avec du Machine Learning.
Quel était le défi qui nous a été présenté ?
Notre client s’est adressé aux experts de Lucy avec un défi clair à résoudre : capturer, intégrer et traiter des jeux de données variés et volumineux, émanant de différentes sources et de solutions ERP propriétaires.
La solution devait répondre aux exigences suivantes :
Etablir une fondation de données intégrées et inclure des capacités d’analyse en temps réel.
Fournir une solution BI moderne avec des capacités de self-service.
Offrir la possibilité de traiter les données avec des outils d’AI/ML pour des cas d’usage prédictifs.
Faire preuve d’agilité et de rapidité pour les évolutions et les déploiements, dans un environnement contrôlé et sécurisé.
Le défi a été relevé par nos équipes.
Approche et solution
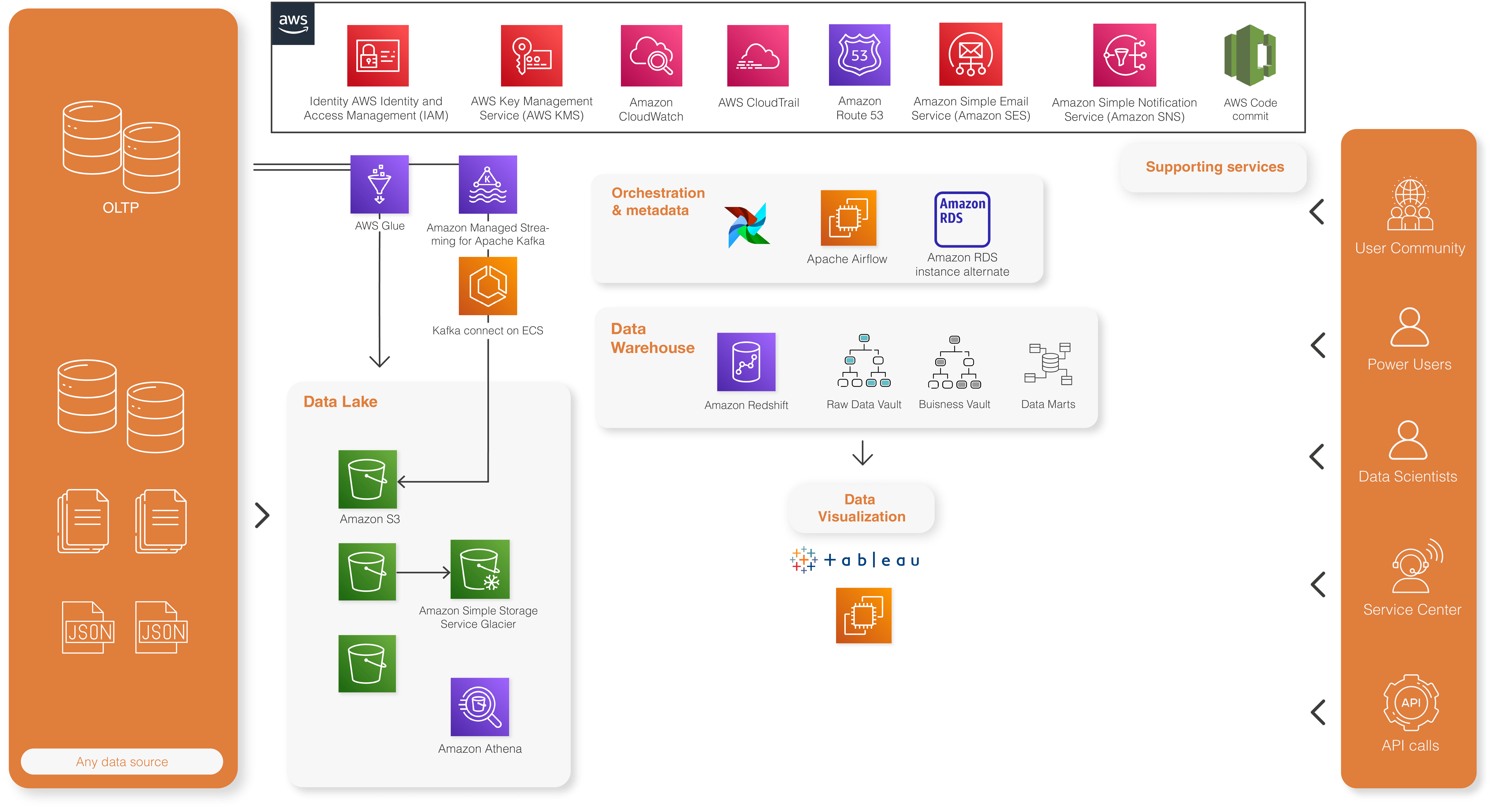
Architecture basée sur les principaux services de données d’AWS
Une approche Lakehouse pour des données unifiées
Nos experts ont conçu et déployé une plateforme de données s’appuyant sur un data lake d’une part et un data warehouse d’autre part, modélisé avec Data Vault 2.0 et s’appuyant sur la technologie Redshift. La méthodologie Data Vault permet un haut niveau de standardisation. Un outil spécifique, développé par les équipes de Lucy, permet d’automatiser les chargements sur base de méta données. La solution est très scalable et s’appuye sur les services serverless d’AWS.
L’utilisation de Tableau avec le plug-in Mapbox permettent alors une visualisation géographique détaillées de toutes les données des compteurs intelligents, avec des temps de réponse très courts.
Des flux de données en quasi temps réel
Les services managés Kafka (MSK) et Kafka Connect sur AWS permettent de capturer et de traiter les nouvelles données émanant de certines sources via un mécanisme CDC (Change Data Capture).
Une architecture Lambda et des capacités prédictives grâce au Machine Learning
Les données de référeces capturées en mode batch, combinées aux données transactionnelles traitées en quasi temps réel via un cluster Kafka forment ainsi une architecture de type Lambda.
Les données intégrées et unifiées au sein du Lakehouse permettent en outre d’activer des capacités prédictives grâce aux outils d’AI/ML proposés par AWS.