Success stories
Health Insurance – Drastically reduce after call work & obtain detailed insights into call reasons

June 3, 2020
The call center of a major health insurance fund wanted to drastically reduce the after-call work of the agent and find the best solution to get detailed insights on the call reasons. Discover how we built an Enterprise Data Platform in the Cloud and implemented AWS AI integrated services to better understand and meet customer expectations.
What was the challenge that we were approached with?
Given the fast evolution of the health insurance market, this health insurance fund wanted to leverage their data in a way that creates more business value. More precisely, they needed to:
- Switch from a traditional descriptive BI to a predictive and even prescriptive approach
- Deploy an agile data environment to implement advanced analytics
- Actively support the company digitalization and new CRM approach
They also asked us to advise on:
- How to transform the organization to support new ways of working with data
- Which technological stack is best fitted to address traditional BI as well as new advanced analytics use cases
- The definition of an implementation roadmap, addressing both the organizational and the technical changes
Our solution: a Cloud-based, Enterprise-wide data platform powered by AWS
We first conducted the current (as-is) and the target (to be) organization and issued a series of recommendations to set the new Data and Advanced Analytics team, redefine the change, build and run processes and introduce a Data Governance approach within the organization.
In a second phase, we deployed the new Cloud-based data environment and rapidly implemented a series of classical BI use cases (using an agile methodology) as well as new, innovative AI and ML use cases, such as automating the processing of Call Center recordings using Speech-to-text and NLP technologies available on the Cloud environment.
Their new data platform is now scaling up fast and is a key enabler to dramatically improve customer experience and implement their digital transformation.
Architecture based upon key data services of AWS
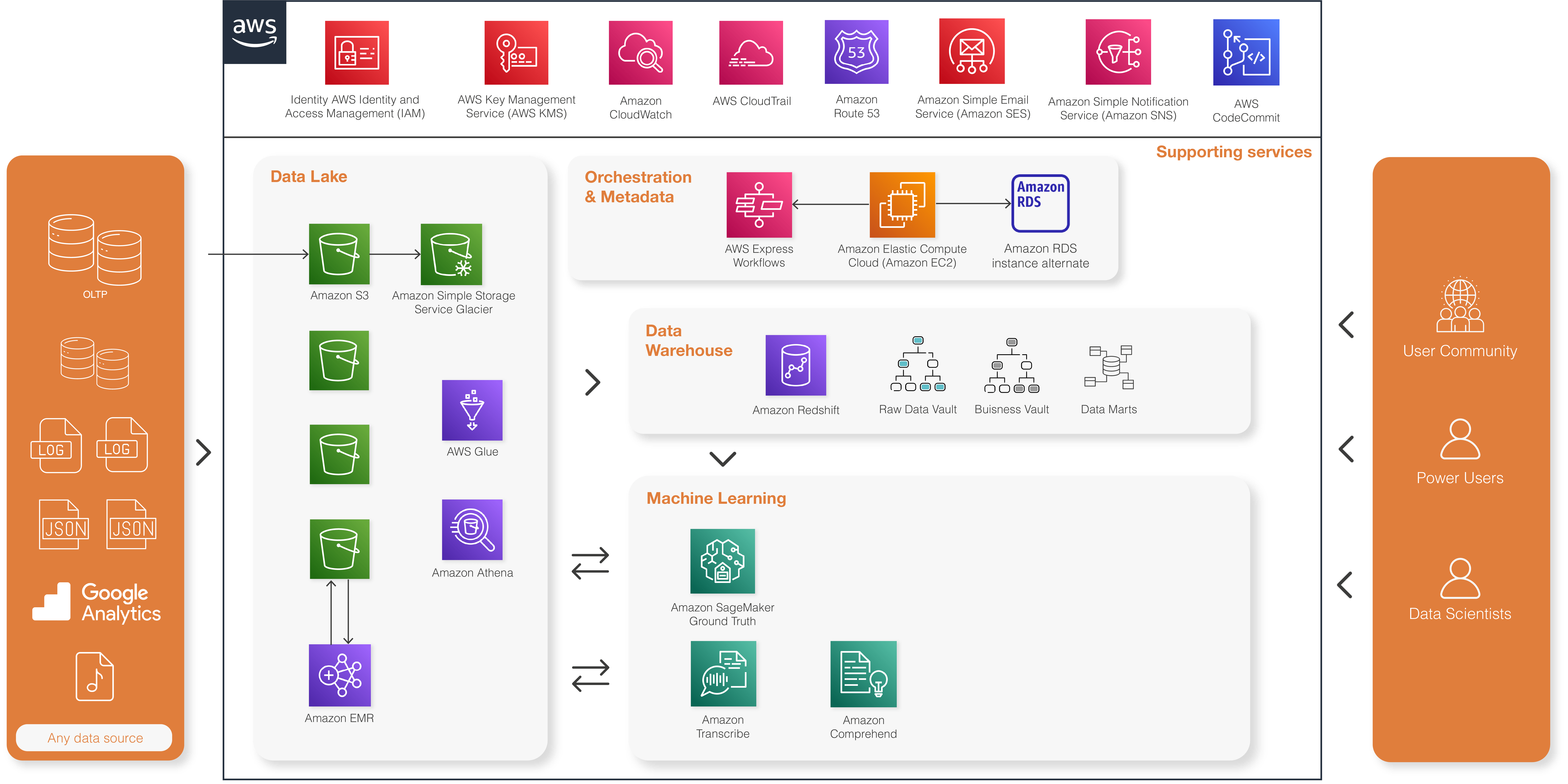
Data Lake
Amazon S3 is used for central inbound layer and achieve long term persistence.
Some data files are pre-processed on Amazon EMR. EMR clusters are created on-the-fly a couple of times per day. The clusters only process new data that arrive in S3. Once the data is processed and persisted in an analytical optimized Apache Parquet format, the cluster is destroyed. Encryption and lifecycle management are enabled on most S3 buckets to meet security and cost-efficiency requirements. 600+ TB of data is currently stored in the Data Lake. Amazon Athena is used to create and maintain a data catalog and explore raw data in the Data Lake.
Real-time ingestion
Amazon Kinesis Data Streams captures real-time data, which is filtered and enriched (with data from the Data Warehouse) by a Lambda function before it is stored into an Amazon DynamoDB database. Real-time data is also stored in dedicated S3 buckets for persistency.
Data Warehouse
The Data Warehouse is running on Amazon Redshift, using the new RA3 nodes and follows the Data Vault 2.0 methodology. Data Vault objects are very standardized and have strict modeling rules, which allows a high level of standardization and automation. The data model is generated based on metadata stored in an Amazon RDS Aurora database.
The automation engine itself is built on Apache Airflow, deployed on EC2 instances.
The project implementation started in June 2017; the production Redshift cluster initially sized on 6 DC2 nodes seamlessly evolved over time and met both the projects growing data needs and answering all business needs.
The automation engine itself is built on Apache Airflow, deployed on EC2 instances.
Amazon DynamoDB is being used for specific use cases where web-applications need sub-second response times. Using the DynamoDB’s variable read/write capacity allows provisioning the more expensive high-performance read capacity during business hours only, where low latency and fast response time are required. Such mechanisms, which rely on the AWS services’ elasticity, are used to optimize the AWS monthly bill.
DynamoDB
Amazon DynamoDB is being used for specific use cases where web-applications need sub-second response times. Using the DynamoDB’s variable read/write capacity allows provisioning the more expensive high-performance read capacity during business hours only, where low latency and fast response time are required. Such mechanisms, which rely on the AWS services’ elasticity, are used to optimize the AWS monthly bill.
Machine Learning
A series of predictive models have been implemented, ranging from a classical churn prediction model to more advanced use cases. For example, a model has been built to spot customers who are likely to have been impacted by a network failure. Amazon SageMaker was used to build, train, and deploy the models at scale, leveraging the data available in the Data Lake (Amazon S3) and the Data Warehouse (Amazon Redshift).
API’s for external access
External parties need to access specific data sets in a secured and reliable way and Amazon API Gateway is used to deploy secured RESTful APIs on top of serverless data microservices implemented with Lambda functions.
And much more!
This Customer Data Platform we have built offers dozens of other capabilities for this Health Insurance operator. The huge set of services available on the AWS environment allows addressing new use cases every day, in a fast and efficient way.